AI-Powered WAFs in 2026: How to Tell a Real Model From a Sticker
Every WAF now claims to be "AI-powered," but the badge covers everything from a real self-learning model to a rule score with a sticker on it. Here is what is actually inside one, where the research shows it gets bypassed, and how to tell real from sticker before you buy.
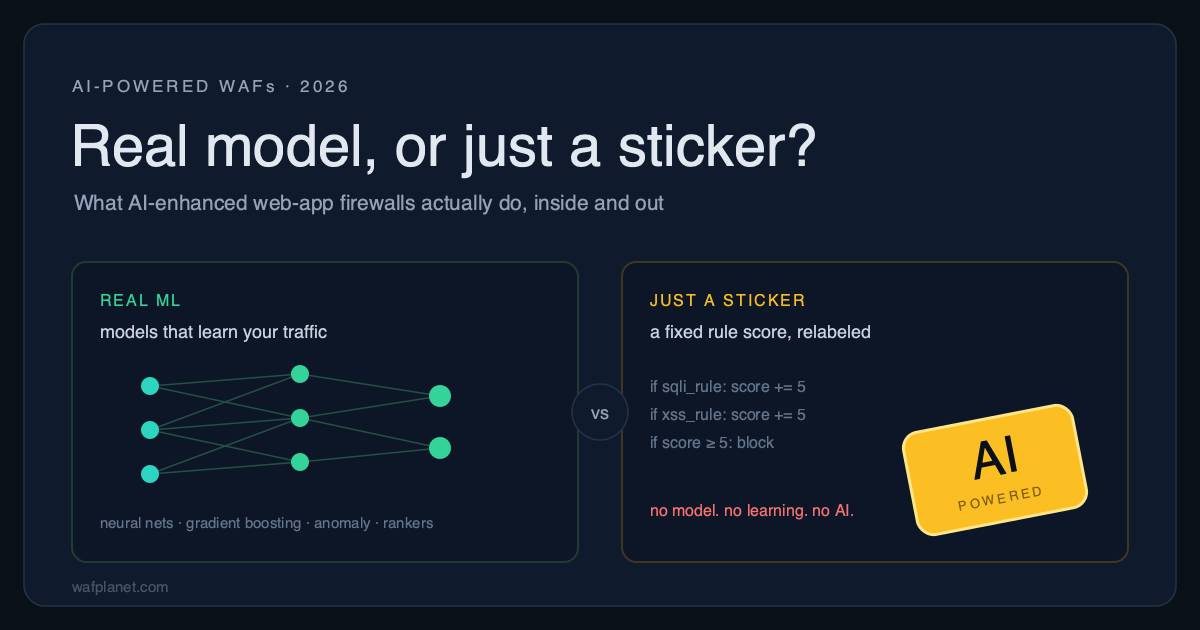
Every WAF on the market now says "AI-powered." On the same spec sheet that badge can mean a model that learns your traffic and catches attacks no signature has ever seen, or a fixed rule score with the word "AI" printed next to it. Same label, opposite products, and the gap between them is the difference between protection and theater.
The shift to machine learning is real and necessary, because attackers now auto-generate attacks at machine speed, spinning out thousands of payloads that mean the same thing and slip every static rule faster than anyone can write one. But "AI-powered" tells you almost nothing by itself, and the same research that proves you need a model also proves the model gets bypassed. So this guide does what the brochures will not: it opens an AI WAF up to show what the "AI" actually is, where it breaks, and how to tell a real one from a sticker before it is live on your edge.
First question: is the "AI" even real?
A WAF decides what to block in one of three ways, and most products blend them. A negative model blocks known-bad patterns and allows the rest: the classic signature WAF, cheap and predictable, blind to anything new. A positive model allows only what is explicitly permitted and rejects the rest: strong against novel attacks, brutal to maintain. Machine learning is the third path, judging traffic statistically by learning what your normal looks like, so it can flag the abnormal, including attacks no signature describes. Source: Check Point
Start with the one distinction vendors lean on most, because the confusion sells. The "anomaly score" in ModSecurity and the OWASP Core Rule Set is not machine learning. Each rule that matches adds a fixed number by severity, a critical rule adds 5, a warning adds 3, and the request is blocked when the total crosses a threshold. That is arithmetic over hand-written rules. No model, no training, no inference. "Paranoia levels" turn the dial by switching on more rules, not by learning anything. CRS is genuinely excellent and underpins most free WAFs. It is just not AI, and a datasheet that calls it AI has told you how to read the rest of the datasheet. Source: OWASP CRS docs
When the ML is real, it comes in two flavors. Supervised models train on labeled good and bad requests: accurate on attack classes they have seen, weaker on the genuinely novel. Unsupervised models get no labels and simply learn the shape of normal traffic to flag outliers: better on the zero-day-shaped request, noisier on false positives, because "unusual" is not the same as "malicious." The best products run both, and rarely with a single algorithm: a real WAF might stack an anomaly detector, a gradient-boosted tree, a deep neural network, and a learning-to-rank scorer that prioritises alerts, swapping them as threats shift. The model family is an implementation detail. What matters for a buyer is the axis, supervised or unsupervised, and where it was trained, which is what everything below sorts into.
The model zoo: which AI actually runs in a WAF
So what are these models, concretely? The brochures almost never say, which is itself telling: of the big vendors, only two clearly name an algorithm, Cloudflare's bot scoring (gradient-boosted trees) and FortiWeb's anomaly layer (a Hidden Markov Model). The rest confirm "machine learning" and stop there. But the families are well understood, and each does a different job. Here is the zoo, and where you actually meet it. Source: Cloudflare (CatBoost) | FortiWeb (HMM)
The model families behind "AI-powered" WAF features. Vendors rarely name the exact architecture, so read the examples as representative, not definitive.
| Model family | What it does in a WAF | Example algorithms | Where it shows up |
|---|---|---|---|
| Anomaly detection | Learns normal traffic, flags the outliers (the zero-day shape) | Isolation Forest, autoencoders, One-Class SVM, Random Cut Forest | open-source ML WAFs; aiwaf |
| Supervised classifiers | Labels a request good or bad, scores bots | Gradient-boosted trees (XGBoost, CatBoost), random forests, SVM | Cloudflare bot scoring (CatBoost) |
| Deep nets on payloads | Catches obfuscated, novel payloads from raw text | CNN, LSTM, Transformer / BERT | Cloudflare WAF Attack Score (neural, inline) |
| HTTP embeddings | Turns requests into vectors for a light classifier | n-grams + TF-IDF, Word2Vec, HTTP2vec | ML feature pipelines; research |
| Sequence and behavioral | Models the normal grammar of parameters and sessions | Hidden Markov Models, LSTMs | FortiWeb (HMM) |
| Clustering and correlation | Collapses thousands of alerts into a few campaigns | k-means, DBSCAN | Imperva Attack Analytics |
| Graph models | Catches coordinated, distributed activity | GCN, GraphSAGE, GAT | bot-fleet and fraud-ring detection |
| Risk scoring | Fuses many weak signals into one per-user score | weighted scoring, learning-to-rank | F5 malicious-user scoring |
| Time-series | Baselines traffic to catch volumetric and behavioral DoS | EWMA, Holt-Winters, change-point | F5 Behavioral DoS; Cloudflare Adaptive DDoS |
| Generative / LLM (assistant) | Explains blocks and tunes rules. Not inline blocking | LLMs | Cloudflare and Microsoft security copilots |
And here is what the table flattens: a serious AI WAF is not one row, it is most of them at once. These families are not competitors, they are specialists, each pointed at the data type it reads best. A deep net or an embedding model on the raw payload text, a time-series model on request rates, a graph model on the relationships between IP addresses, a Hidden Markov Model on the grammar of a session, clustering on the alert stream, and the scores fused into a single allow-or-block decision. So "which model does it use" is the wrong question. The right one is whether it brings the right model to each signal and combines them well.
Two cautions the table earns. That last row is the one to watch: a generative-AI copilot that explains a block or drafts a rule is genuinely useful, but it reads logs after the fact and makes no inline decision, so a product whose only "AI" is a chatbot is back to selling you a sticker. And do not over-read the examples, because outside those two disclosures the vendors confirm machine learning but not which model. You judge them the way the rest of this guide does: is it tunable, is it independently tested, and where does it train, not by a model name they will not even give you. Survey: Deep Learning for Web Attack Detection, Future Internet 2022
Inside a real one: the six numbers behind an open-source AI WAF
Most commercial ML WAFs are black boxes. aiwaf is not, and that makes it the perfect way to see what the "AI" concretely is. It is a small, MIT-licensed Python WAF, with adapters for Django, Flask, and FastAPI, whose entire model you can read in an afternoon. It is early-stage, roughly 55 stars and still on 0.1.x, so treat it as a teaching example, not enterprise software. But the patterns it teaches are exactly the ones the expensive products run behind the curtain. Source: aiwaf on GitHub | DjangoCon US 2025 talk
Here is the surprise for anyone expecting a neural network. The entire model is an Isolation Forest from scikit-learn, an unsupervised algorithm that isolates outliers, fed exactly six numbers per request.
# Simplified from aiwaf (MIT). The whole "AI": an Isolation Forest
# over six features pulled from your OWN access logs. No labels,
# no signatures. It learns normal and flags the outliers.
from sklearn.ensemble import IsolationForest
# contamination = expected fraction of anomalies (aiwaf default: 0.05)
model = IsolationForest(contamination=0.05, random_state=42)
# one row per request, six numbers each:
features = [
path_len, # length of the URL path
kw_hits, # count of suspicious keywords in the path
resp_time, # how long the response took
status_idx, # index of the HTTP status code in a fixed list
burst_count, # requests from this IP in the last 10 seconds
total_404, # cumulative 404s seen from this IP
]
model.fit(training_matrix) # retrained nightly, on recent logs
prediction = model.predict([features]) # -1 = anomaly, 1 = normalThe model at the heart of one open-source AI WAF: six features and an Isolation Forest, retrained on your own traffic. Adapted and simplified from aiwaf's trainer.
Two things in that small picture generalize to every AI WAF, the expensive ones included.
It learns from your traffic, which is the point and the catch. The "normal" aiwaf learns is genuinely yours. But it will not fit the model at all until it has seen 10,000 requests, and does nothing below 50. Until then it runs on rate limiting and keyword learning alone. Every self-learning WAF pays this cold-start tax: on day one it has digested nothing. Commercial products hide it by shipping a model pre-trained on other people's traffic, which is precisely the tradeoff we weigh under cost.
The model is one layer, not the whole defense. aiwaf does not block on an anomaly score alone. A -1 only blocks after a cross-check against a 300-second behavioral window, and the real day-to-day blocking comes from distinctly un-glamorous layers around it: a sliding-window rate limiter, keyword learning that mines suspicious tokens from the paths of 404 and 5xx responses, time-based honeypots that catch forms submitted impossibly fast, header validation, and GeoIP. The ML catches what the rules miss. It does not replace them. That is the shape of every serious product.
What does not generalize is the model itself. aiwaf's Isolation Forest is the simplest end of the spectrum, picked here because it is tiny and readable. Production WAFs reach for heavier and more varied machinery: gradient-boosted trees, deep neural networks, sequence models, ensembles, and rankers, often several at once and retrained far more aggressively. So do not read "Isolation Forest" as "what an AI WAF is." Read it as the cheapest thing that already works, and assume the commercial products are doing something bigger under the same two patterns above.
Does it actually work? Where AI WAFs break, with receipts
This is the part the marketing skips, and it should shape your whole purchase. A machine-learning WAF is a probabilistic filter, and a determined attacker treats it as a system to be solved, not a wall to be climbed.
The foundational result is WAF-A-MoLE, the tool from the intro. It mutates a SQL-injection payload with operators that "alter the syntax of a payload without affecting the original semantics," so the attack still works but no longer matches the training data, and it bypasses every machine-learning WAF the paper tested. The follow-on work is worse for the defender. AdvSQLi (IEEE TIFS, 2024) is black-box, needing no access to the model's internals, and reports a "maximum attack success rate of 100%" against state-of-the-art ML SQL-injection detectors, "over 79%" against the F5 WAF, and finds all seven tested WAF-as-a-service products vulnerable. Source: WAF-A-MoLE, arXiv:2001.01952 | AdvSQLi, arXiv:2401.02615
There is a defense, and it is the single best question to put to a vendor. Adversarial training, deliberately fitting the model on these evasive payloads, measurably hardens it: the ModSec-AdvLearn work shows up to 85% better robustness and 30% better detection while discarding up to half the rules. So the question is never "do you have a model." It is "do you adversarially test and retrain it against current evasion research, and how often." A vendor that cannot answer is selling the 2019 version of this. Source: ModSec-AdvLearn, arXiv:2308.04964
And a WAF that retrains on live traffic opens a second door: poisoning. If the model learns "normal" from traffic an attacker can shape, a patient adversary can drift the baseline over days until their attack reads as ordinary. No one has demonstrated this against a production ML WAF yet, so treat it as a theoretical risk, not a proven exploit. But it is the obvious next move, and it is why "continuously trains on your traffic" is a feature and a liability in the same breath.
One more receipt, and this one cuts both ways. A 2022 survey pooled 63 deep-learning studies on web-attack detection, and the reported scores are gaudy: accuracy clusters around 0.98 to 0.99 across the board. Then look at what they were tested on. Nearly half (28 of the 63) benchmark on CSIC 2010, a dataset published in 2010, and most of the rest use private sets that were never released. Those numbers are a lab ceiling on stale, often unreproducible data, not a promise about your traffic.
The window cuts both ways too. The studies span 2010 to 2021, and the deep-learning surge (AlexNet in 2012, the transformer in 2017) reshaped the field partway through, so the early results are a different era of modeling. But the same dates carry a signal the other way: a vendor that was already publishing machine-learning attack detection back then has been compounding that work for a decade, and is far likelier to be at the front of it now than one that discovered "AI" for a 2024 press release.
And the limitations the authors flag over and over, adversarial evasion, restricted datasets, retraining per application, online updating, are the same failure modes WAF-A-MoLE and AdvSQLi exploit above. The full evidence is below, collapsed. Expand it for the texture. Source: Future Internet 2022, Table 5
The landscape: where the machine learning actually is
With "is it real" and "where does it break" settled, here is who does what. Read the third column first. A model trained on a vendor's global network gives you threat signal you could never gather alone, but it is reading your traffic to do it. A model trained only on yours keeps everything in house and sees nothing of the campaign hitting a thousand other sites first. That tradeoff, more than any feature, is the decision.
Where the machine learning actually lives, mid-2026. The last row is the myth-buster, not a typo.
| Product | Learns by | Trained on | Runs |
|---|---|---|---|
| Cloudflare Attack Score | Supervised | Cloudflare's global network | Cloud |
| Akamai App & API Protector | Adaptive anomaly + auto-tuning | Akamai's global network | Cloud |
| Imperva | Behavioral + attack analytics | Your traffic, plus Imperva research | Cloud |
| F5 BIG-IP / Distributed Cloud | Behavioral baselining | Your own traffic | Self-host or cloud |
| Fortinet FortiWeb | Two-layer (HMM + threat models) | Your traffic, plus FortiGuard | Appliance or cloud |
| open-appsec | Supervised and unsupervised | Global, plus your app | Self-host or cloud |
| Prophaze | Behavioral + ML | Your own traffic | Kubernetes or cloud |
| AWS WAF Bot Control | Unsupervised, bots only | Your traffic | Cloud |
| aiwaf | Unsupervised | Your access logs | Self-host |
| ModSecurity + OWASP CRS | Nothing. It is rules | Not trained | Self-host |
Three of those are worth a closer look, because each is a clean example of a different way to do this well. Then a reality check on whether any of it earns its keep.
Cloudflare: supervised learning at industrial scale
Cloudflare's WAF Attack Score is the textbook supervised model done at a scale almost nobody else can match. It is a classifier trained on traffic Cloudflare's existing rules already labeled, and it scores every request from 1 to 99, where 1 is almost certainly an attack and 99 is almost certainly clean. You pick a threshold and block beneath it. The interesting part is the engineering: running a model inline on a meaningful slice of the internet is a latency problem, and Cloudflare ground per-request inference down to roughly 275 microseconds with quantization, SIMD, and caching. This is what "AI-powered" looks like when it is real and industrialized, and the price of admission is that your requests are scored on Cloudflare's edge, by a model trained on everyone's. Source: Cloudflare | edge latency
open-appsec: the open dual-model you can run for free
open-appsec, from Check Point, is the most interesting option for anyone who wants real ML without a black box. It runs two models at once: a supervised model trained offline on millions of malicious and benign requests, plus an unsupervised model "built in real time in the protected environment" that learns your specific app, combined into one confidence score that decides allow or block. It markets pre-emptive zero-day coverage (it caught Log4Shell-class attacks with no signature update) and plugs into NGINX, Kong, Envoy, and Istio. The agent is Apache-2.0 and free to self-host, the basic model is included, and the advanced model is a proprietary download. It is the rare product that spans a free self-hosted agent and a managed SaaS tier (from $79 to $109 a month depending on billing term, including 1M to 10M requests a month), which is exactly the flexibility most buyers underrate. Source: open-appsec docs
FortiWeb: the two-layer design built to fight false positives
Fortinet's FortiWeb is the cleverest architecture of the three, and it is built around the real enemy of ML WAFs, which is not missing attacks but crying wolf. Layer one is a Hidden Markov Model that learns a mathematical baseline for every parameter and every HTTP method from your traffic. When something deviates, layer two kicks in: a set of pre-trained threat models, one per attack category, decides whether the anomaly is an actual attack or just unusual-but-benign. The first layer catches the abnormal; the second exists specifically to stop the first from blocking your legitimate users, and the threat models are kept current through FortiGuard. It runs on the box, so your traffic does not leave for a vendor cloud. Source: Fortinet FortiWeb docs
The rest of the field: Prophaze, Wallarm, Radware, and more
Those three are illustrative, not a shortlist. Several other genuine ML WAFs are worth a look depending on your stack. Prophaze builds behavioral ML natively on Kubernetes, the easiest of these to drop into a cloud-native cluster. Radware auto-generates a positive-security policy from your own legitimate traffic. Wallarm uses a signatureless, grammar-based approach to injection detection and adds ML baselining for APIs, the exact area the independent tests show everyone struggling with. Gcore and Reblaze run detect-mitigate-adapt loops at the edge. And the two cloud incumbents the independent tests keep naming as leaders, Akamai and Imperva, both layer real ML onto mature platforms.
The reality check: do any of them actually work?
Do any of them earn it? The closest thing to a neutral answer is SecureIQLab's 2025 Cloud WAAP validation, which threw more than 1,360 attacks at 11 commercial WAAPs. The averages are sobering: 74.5% security efficacy overall, a healthy 89.5% on the OWASP Top 10, and only 55% on OWASP API attacks, the soft underbelly nobody markets. Named leaders were Akamai, Fortinet, Imperva, and Traceable by Harness, with complete-security scores ranging from Akamai's 88% down to AWS's 42%. The lesson is not which logo won. It is that even the best miss a real fraction of attacks, and that API coverage lags web coverage badly. SecureIQLab's v5.0 round, the first to test AI defenses with AI attacks, lands around late July 2026. If you buy before then, buy provisionally. Source: SecureIQLab Cloud WAAP v4.0
The red flags: spotting AI-washing
"AI-washing," overstating the role of AI to sell a product, is common enough that the SEC has fined companies for it, going after advisers who claimed to use AI models they did not actually run. Source: SEC, March 2024
"Investment advisers should not mislead the public by saying they are using an AI model when they are not. Such AI washing hurts investors."
The same instinct shows up on a WAF in four repeatable moves, each a real 2026 example.
- Rule scoring dressed as a model. CRS-style anomaly scoring relabeled as machine learning. Real, useful, not AI. The fastest tell on any datasheet.
- A chatbot mistaken for the engine. Fortinet's "FortiAI" assistant is a generative-AI copilot for investigating logs and writing reports. Pleasant, and nothing to do with the ML that actually detects attacks. When "AI" turns out to mean "it explains the dashboard," it is not protecting anything. Source: Fortinet
- AI at setup time sold as AI at runtime. Barracuda's 2026 login feature uses machine vision and OCR to auto-discover login pages and generate policies. That is AI helping you configure, not a model inspecting live attacks. Ask where in the request path the "AI" actually sits. Source: Barracuda
- A black box with no evidence. No tunable threshold, no explanation of why a request was blocked, no independent efficacy numbers, no answer on adversarial-testing cadence. That is not a model you are buying, it is faith.
How to choose: cost, control, and staying ahead
Strip away the brochures and the decision is one axis: who trains the model, and therefore where your data and your control live. The table below is the whole choice on one screen.
Self-hosted and open-source is the floor on spend and the ceiling on control. aiwaf is free on a single CPU; open-appsec's agent is free to self-manage; FortiWeb runs its models on the box. You pay in engineering time, in the compute the model burns per request, and in the cold-start period while it learns you. In return your traffic never leaves, you can tune and inspect the model, and there is no lock-in. The cost is a model that only knows your traffic, blind to the campaign hitting others first. This is the same instinct we argued for self-hosted inference in Part 2 of our inference series: when the data is sensitive and you have the engineering, keep the whole pipeline in your own boundary.
Proprietary cloud is the opposite trade, and not all downside. Cloudflare, Akamai, and the rest train on enormous aggregate traffic, so an attack on one customer hardens the model for all, and a small site inherits a huge network's threat intelligence with a model that works on day one and no GPU bill. The cost is the red-flag list: your traffic transits the vendor, you inherit their data handling, and you are usually looking at a black box. Flexibility is the tiebreaker most buyers skip: a product you can run free and self-hosted today and managed tomorrow, or point at a different stack without re-buying, leaves you a door. One welded to a single edge locks you in the room.
The decision on one screen. Self-hosted means open-appsec, FortiWeb, aiwaf, or Prophaze; cloud means Cloudflare, Akamai, Imperva, or Gcore.
| What matters | Self-hosted | Cloud / SaaS |
|---|---|---|
| Trains on | Your traffic only | Everyone's traffic |
| Your data | Never leaves your environment | Transits the vendor |
| Threat signal | Local only | Global, across all customers |
| Day one | Cold start while it learns | Works immediately |
| Tuning | You tune and inspect it | Usually a black box |
| What you pay | Your compute and engineering | Usage-based, scales with traffic |
| Lock-in | None / Implementation Complexity | Vendor, often a single edge |
And "future-proof," stripped of marketing, means exactly one measurable thing: the model improves faster than the research keeps finding ways around it, and you can see that it does. Concretely, that means a vendor who adversarially tests and retrains against evasion research, who layers ML on top of signatures rather than betting everything on one classifier, who lets you tune and inspect and leave, and who is honest that even the leaders miss real attacks. Anything you cannot measure, you are taking on faith, and faith is not a security control.
The takeaway: judge the thing, not the label
Machine learning in the WAF went from luxury to table stakes, because attacks now rewrite themselves faster than anyone can write signatures. But "AI-powered" on the box spans a genuine self-learning engine and a renamed rule score, so judge the thing, not the label. Confirm it is real ML and not CRS scoring with a sticker. Confirm it is adversarially tested, independently validated, tunable, and layered on top of signatures rather than replacing them. Self-host when your data and control matter and you have the engineering; pay for the cloud when global threat intelligence is worth sending your traffic away. And whatever you choose before the independent 2026 numbers land, choose it provisionally.
To run the open dual-model yourself, start with open-appsec. To actually read how the AI part works, read aiwaf. If you are protecting an AI application rather than a web app, that is the other problem, and it lives in our secure inference series. And for the battle-tested non-AI options while this market settles, our free WAF rankings are where to look.
Frequently Asked Questions
What does "AI-powered WAF" actually mean, or is it just marketing?
It is a real capability and an overused label, which is why you have to look past it. A genuine AI-powered WAF uses a machine-learning model, supervised, unsupervised, or both, to judge whether a request is malicious from patterns it learned in traffic, rather than only matching fixed signatures, which lets it flag novel attacks no rule describes. But the same phrase gets stuck on products whose "AI" is really deterministic rule scoring, a GenAI chatbot that explains your dashboard, or a setup wizard. The test is simple: ask what the model is, what it trained on, whether you can tune and inspect it, and whether it has independent efficacy results. Real answers mean a real model.
Is ModSecurity or the OWASP Core Rule Set "AI"?
No. The CRS "anomaly score" is arithmetic over hand-written rules: each rule that matches adds a fixed number by severity, and the request is blocked when the total crosses a threshold. There is no model, no training, and no inference. "Paranoia levels" increase sensitivity by enabling more rules, not by learning. This matters because CRS-style scoring is frequently marketed as machine learning, and it is the most common form of WAF AI-washing. CRS is genuinely excellent and underpins most free WAFs; it is just not AI, and a vendor that conflates the two is one to read carefully.
Can an AI-powered WAF be bypassed?
Yes, and the research is unambiguous. WAF-A-MoLE mutates attack payloads so they keep working but no longer resemble the training data, and bypassed every ML WAF it tested. AdvSQLi, a black-box attack needing no access to the model, reported up to a 100% success rate against state-of-the-art ML SQL-injection detectors, over 79% against the F5 WAF, and found all seven tested WAF-as-a-service products vulnerable. The defense is adversarial training, deliberately fitting the model on evasive payloads, which measurably hardens it. So an AI WAF is a probabilistic filter, not a wall. Ask any vendor how often they adversarially test and retrain against current evasion techniques.
Should I self-host an open-source AI WAF or buy a cloud one?
It comes down to data and threat intelligence. Self-hosting (aiwaf, or open-appsec self-managed, or FortiWeb's on-box models) keeps all your traffic in your environment, lets you tune and inspect the model, and avoids lock-in, at the cost of engineering time, your own compute, a cold-start period while it learns, and no view of attacks hitting other sites. A cloud WAF trains on huge aggregate traffic, so you inherit global threat signal and a model that works on day one, at the cost of sending your traffic to the vendor, usually a black box, and usage-based pricing. If your data is sensitive and you have the team, self-host. If global threat intelligence matters more than data residency, buy cloud, and put data-handling terms in the contract.
Does an AI WAF replace my signature rules?
No, and any product that says it does is the one to distrust. Because ML models are demonstrably evadable, the model has to be one layer in defense in depth, not the whole defense. Every serious product, and even small open-source ones, wraps the model in classic controls: signature rules, rate limiting, IP reputation, and heuristics like honeypots and header validation. The model catches what the rules miss, especially novel attacks, while the rules catch the known attacks cheaply and predictably. Run them together. A WAF that bets everything on a single classifier is betting on the exact thing the evasion research keeps breaking.
How do I spot AI-washing in a WAF product?
Ask precisely what the "AI" is and where it sits in the request path. Four real 2026 patterns: deterministic rule scoring relabeled as machine learning; a GenAI assistant that summarizes logs sold as the detection engine (Fortinet's FortiAI is the copilot, not FortiWeb's actual ML detection); machine learning that runs at configuration time rather than runtime (Barracuda's vision-based login-page discovery); and a black-box model with no tunable threshold, no explainable decisions, and no independent efficacy results. None are scams, but none are "a model inspecting your live traffic," which is what you are usually trying to buy. Demand the model description, the false-positive rate, and the adversarial-testing cadence in writing.
How much does an AI-powered WAF cost?
From free to enterprise-opaque. Open-source ML WAFs (aiwaf, open-appsec's self-managed agent) are free to license; you pay in engineering time and the compute the model uses per request. open-appsec's managed SaaS runs roughly $79 to $109 per month for single-digit-millions of requests as a public anchor, while most enterprise WAAP pricing is "contact sales," meaning usage-based and negotiated. But price is the smaller half of the decision. The bigger cost is architectural: a cloud model means your traffic transits the vendor and you inherit a black box, while self-hosting means you own the compute, the tuning, and the cold-start period. Decide the data-and-control question first, then compare prices within that choice.