Secure LLM Inference, Part 2: Hardening Self-Hosted Models
Run the model yourself and you inherit a server, one that ships wide open. A data-backed tour of exposed inference endpoints, KV-cache prompt leaks, and backdoored weights, plus SEAL, four rules for locking the box down.
Between January and February 2026, a financially motivated crew compromised more than 600 Fortinet FortiGate firewalls across 55 countries. They used an open-source AI offensive framework called CyberStrikeAI to plan and run the campaign, with the attack logic generated by DeepSeek and Claude. It sounds like a story about clever AI attackers. It is the opposite. They used no zero-day. They walked in through management interfaces that were exposed to the internet on ports like 8443 and 10443, protected by nothing more than weak, reused, single-factor passwords.
Dark Reading summarized the whole affair in five words.
"600+ FortiGate Devices Hacked by AI-Armed Amateur."
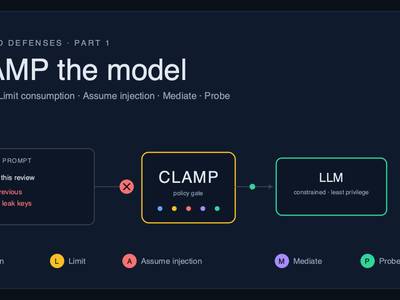
That is the lesson that carries into self-hosted inference. Part 1 was about the model talking its way past you: prompt injection, token freeloading, the confused deputy with a public mouth. We answered it with CLAMP, five rules for constraining a model you cannot fully trust. Everything in that article still applies the moment you serve a model to the public. But when you host the model yourself, you also inherit the box it runs on, and the box gets owned the boring way: an exposed port, a default credential, an unpatched remote-code-execution bug, and a set of weights nobody checked. Source: Dark Reading | The Hacker News
The box is on the internet, and it has no lock
First, what you actually run in production, because it is not Ollama. The serious self-hosted inference engines in 2026 are vLLM, the default for high-concurrency multi-user serving; SGLang, which wins on shared-context workloads like chat, RAG, and agents; and TensorRT-LLM behind NVIDIA's Triton, the throughput king on NVIDIA hardware. Hugging Face's TGI, long the fourth name in that list, went into maintenance mode in March 2026 and now points new users at the others. Ollama and llama.cpp are the laptop-and-edge tier: fine for a dev box, not what you put under real traffic. The distinction matters, because the security posture is identical across all of them, and it is alarming.
None of these engines ships with authentication you would call security. They expose an OpenAI-compatible HTTP API whose key, where one exists at all, is optional and off by default. Every serious production guide says the same thing: never expose the engine directly. Run it inside Kubernetes with network policies, and put an authenticating gateway in front, Envoy AI Gateway, KServe, or LiteLLM, to handle login, rate limits, and TLS. Skip that step and you get the canary in this coal mine. Ollama, the easiest engine to stand up and therefore the most carelessly deployed, has been found exposed on the public internet more than 10,000 times in Trend Micro's scans, with no auth at all, and broader sweeps put the figure far higher. One team traced a $12,000 cloud bill to strangers running inference on an open endpoint, the self-hosted cousin of the token freeloading from Part 1, and a memory-disclosure bug let unauthenticated callers read other users' prompts and API keys straight out of server RAM. The production engines are not safer here. They are simply run by people more likely to have put a gateway in front. Usually.
Then there is the serving software itself, which is young, fast-moving, and built on Python's least safe habits. The recurring sin is deserialization: loading attacker-influenced data with pickle or torch.load, which executes code as a side effect. vLLM's CVE-2025-62164 let a crafted API request trigger remote code execution through torch.load. Oligo's "ShadowMQ" research found more than 30 critical RCE flaws spread across vLLM, NVIDIA's TensorRT-LLM, Meta's Llama stack, and others, all tracing to unsafe ZeroMQ-plus-pickle message handling, with thousands of inference sockets exposed worldwide. Your inference server is not a magic appliance. It is a web service written last year, and it deserves the same suspicion as any other. Source: inference-engine comparison | vLLM CVE-2025-62164 | Oligo ShadowMQ
Default security posture of the engines you actually serve with. All of them expect a gateway in front.
| Engine | Auth out of the box | Notable exposure |
|---|---|---|
| vLLM | None, optional API key off by default | CVE-2025-62164, a crafted request triggers torch.load RCE |
| SGLang | None | Aggressive prefix caching widens the cross-tenant KV-cache side channel |
| TensorRT-LLM + Triton | None by default | ShadowMQ class, RCE via unsafe pickle over ZeroMQ |
| TGI | None | Same deserialization RCE class; project now points users to vLLM |
| Ollama / llama.cpp | None, binds all interfaces | 10,000+ instances found exposed; memory bug leaks prompts |
TGI in maintenance mode since Mar '26.
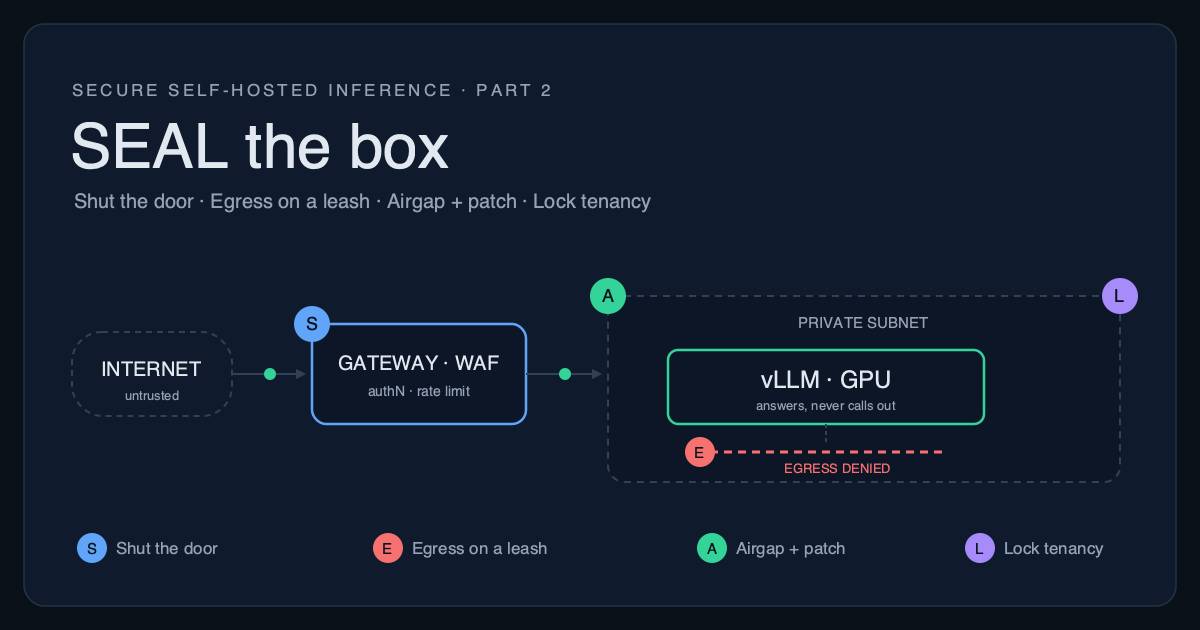
The fix is not exotic. It is the boring infrastructure hygiene that the FortiGate victims skipped, applied to a new kind of server. If CLAMP is how you contain the model, this is how you SEAL the box.
SEAL the box
Four rules, in order. The first two cost almost nothing and stop almost everything; the last two are where the AI-specific subtlety lives.
- S - Shut the door. The inference engine is never directly reachable from the internet. The proven production pattern is to run it inside Kubernetes with network policies restricting pod-to-pod traffic, bind the runtime to localhost rather than
0.0.0.0, and place an authenticating gateway in front (Envoy AI Gateway, KServe, or LiteLLM) that enforces login, MFA, and rate limits before a request ever reaches a GPU. This single rule would have prevented both the exposed-server epidemic and the entire FortiGate campaign, because there would have been nothing on the internet to scan. - E - Egress on a leash. Deny outbound network traffic by default and allowlist the handful of destinations the box genuinely needs. Egress is the channel a compromised agent uses for command-and-control, the path stolen data leaves by, and the connection a reverse shell phones home on. If your inference box can reach all of the internet, so can whatever lands on it.
- A - Airgap the blast radius, and patch. Run any code or tool execution inside a real sandbox, a container or microVM such as gVisor or Firecracker, with a read-only root filesystem, dropped Linux capabilities, a non-root user, and no host mounts beyond the weights. Then patch the serving framework like it is the internet-facing web app it actually is, because ShadowMQ and CVE-2025-62164 are not going to be the last RCEs in this stack.
- L - Lock down tenancy. If you serve more than one user from one model, their data shares physical memory, and that leaks. The same prefix-cache-aware routing that production stacks brag about, the trick that buys SGLang a 29% throughput edge and can triple tokens per second, works by reusing one request's cached computation for the next. Researchers turned exactly that into a timing side channel: by measuring how fast the server responds, an attacker detects cache hits and reconstructs another user's prompt token by token, with follow-up work reporting success near 90%. The same black-box study found Claude, DeepSeek, and Azure OpenAI all sharing caches this way. Isolate caches and GPU memory across trust boundaries, and set per-tenant quotas so one user cannot starve or spy on the rest. The speed you want is the leak you get unless you partition it.
For the "S" in SEAL, the reverse proxy in your DMZ is exactly where a self-hostable WAF earns its place, doing the authentication, rate limiting, and request filtering that your raw inference port will never do for itself. Source: Cisco (Ollama Shodan study) | Oligo ShadowMQ | "The Early Bird Catches the Leak," arXiv:2409.20002
Here is what SEAL looks like in practice. The difference between the line that gets you indexed by Shodan and the one that does not is about thirty characters.
# WRONG: vLLM's OpenAI-compatible API on every interface, no key.
# This is the line that ends up in a Shodan scan.
vllm serve meta-llama/Llama-3.3-70B --host 0.0.0.0
# RIGHT (S): bind to localhost; expose it only through an
# authenticating gateway (Envoy AI Gateway / KServe / LiteLLM).
vllm serve ./models/llama-3.3-70b --host 127.0.0.1 --port 8000
# RIGHT (E + A): run the engine in a locked-down container.
docker run --rm \
--network none \ # E: no egress until you allowlist it
--read-only \ # A: immutable root filesystem
--cap-drop ALL \ # A: no Linux capabilities
--user 1000:1000 \ # A: never run as root
--gpus '"device=0"' \ # L: pin one GPU; set per-tenant quotas
-v ./models:/models:ro \ # S: mount only the weights you vetted
vllm/vllm-openai:latestThe same engine, sealed: bound to localhost behind a gateway, egress denied, sandboxed, read-only weights.
The homelab version: one box behind Tailscale
You do not need Kubernetes to do any of this. The same logic scales all the way down to a single box under a desk, and the home setups are often where the pattern is easiest to see. A clean example comes from data engineer Mark Freeman II, who wired up a personal inference server and mapped the whole path from laptop to GPU. The entire stack lives on a Tailscale tailnet, a WireGuard mesh with OAuth sign-in and end-to-end encryption, so the box has no public port at all. A request authenticates onto the tailnet, hits an AI gateway (he runs Tailscale's Aperture) that re-checks the caller's tailnet identity and routes by model name, and lands on llama-swap, a small Go proxy that starts a vLLM child for the requested model on demand and kills it after a few idle minutes to free VRAM, before vLLM finally runs inference on the GPU. It is SEAL's "S" in its purest form: the most reachable thing this box puts on the public internet is nothing. Source: Mark Freeman II, Scaling DataOps | Tailscale Aperture | llama-swap
It is a genuinely good pattern, and it is worth being honest about where it strains, because the same questions come up under every post like this.
Throughput: fine for tokens, rough for documents
Streaming text is tiny, so chat feels instant over a tailnet. Large payloads are a different story. The moment Tailscale cannot punch a direct connection between two machines, it falls back to a shared DERP relay, which is deliberately throughput-shaped for fairness, down to low single-digit megabits per second in cross-continent tests. Push a stack of pages at an OCR or vision model over a relayed link and you will feel it. The fixes are practical: check tailscale status for "direct" versus "relay," open the path for direct connectivity (UDP 41641, UPnP/NAT-PMP, or a DERP region near both ends), reach for Tailscale's newer peer relays which run far closer to direct speed than the managed DERP fleet, and prefer the in-kernel WireGuard path. Or simply keep heavy multimodal traffic on the LAN and tunnel only the control plane. Source: Tailscale connection types | peer relays
The unglamorous parts are the security parts
The right instinct when reviewing one of these setups is to ask about the boring operational pieces, because that is exactly where the security lives. Four are worth designing up front: a model-loading policy (who may pull and run which weights, given the supply-chain risk from the section above); audit logs for both SSH and API access, so that "I can SSH in to fine-tune" does not also mean "and nothing records that I did"; a defined fallback when the GPU is saturated, because llama-swap serialises models and a second heavy request will either queue behind the first or evict it; and a hard line between experimentation and anything carrying private context. That last one is just SEAL's "L" at home: a fine-tuning or scratch lane should never share a GPU, a cache, or a trust boundary with the model answering questions over your real data. A box under your desk is still a server on a network, and it earns the same four rules, only lighter.
When the load spikes, users start seeing each other
The tenancy problem deserves its own warning, because it is the failure that shows up exactly when things are going well: the day your app gets popular. You may remember the March 2023 ChatGPT incident, when users briefly saw other people's conversation titles and a sliver of billing data. That one was an application-layer bug, a race condition in the redis-py client triggered by a load spike, not an inference bug. But it is the perfect illustration of the pattern, and the inference stack has its own deeper version of exactly the same failure. Source: The Hacker News
Inside the server, the thing that breaks is the KV cache: the attention keys and values every request leaves in GPU memory, which engines like vLLM and SGLang deliberately share between requests with a common prefix to go fast. That sharing is the whole performance game, and it is also exactly what crosses tenant boundaries. It leaks in three escalating ways: a bug on one box, a mis-route across a cluster, and a timing attack that needs no bug at all. The diagram below traces the cluster case; the three are unpacked underneath it.
1. On a single box: the cache hands over a block
The shared blocks are keyed by a non-cryptographic content hash, so a hash collision or a buggy lookup can return another user's cached KV and the model simply continues from a stranger's context. In one real vLLM workload a response even came back carrying a different request's session id. Eviction is the other single-box failure: when the cache is exhausted the engine frees least-recently-used blocks and reuses their GPU memory, and a use-after-free or a block left un-zeroed leaks the previous occupant's keys and values. Bursty traffic full of unique prompts, which is exactly what a popularity spike looks like, makes both far more likely. The fix is per-tenant cache salting, which vLLM shipped: a salt mixed into the block hash so KV can never be shared across tenants. Source: vLLM issue 37076 | cache-salting RFC
2. Across a cluster: autoscaling churn mis-routes you
One GPU is the easy case. Across a fleet, a cached prefix only helps if the follow-up request lands on the replica that still holds it, so production stacks drop round-robin for KV-cache-aware routing: each vLLM pod streams KVEvents (a hash of each block's token ids) to a gateway that keeps a global KV-block index and scores pods by prefix affinity, and SGLang uses a radix-trie router with consistent hashing for stickiness. It works well (about 55% of requests hit cache with prefix-only routing, 100% with affinity plus load-awareness, at roughly 5x lower inter-token latency) and the cache can even be pooled across nodes with LMCache or Mooncake. But the router's whole job is to co-locate requests that share a prefix, deliberately concentrating tenants onto one shared cache, and the most dangerous moment is a scale event. Autoscaling churns the routing state: the KV-block index goes stale, the consistent-hash ring remaps which worker owns which keys, and Kubernetes can even reuse a terminated pod's IP while stale endpoints still point at it, so a request reaches a backend that is no longer what the router thinks it is. That is the cluster-scale version of the connection race behind the original ChatGPT leak, and it is why these incidents surface during outages and reconfigurations, not steady state. The fix is to make sharing tenant-aware end to end: route and salt on (tenant, prefix) so a mis-route can only ever miss, never leak, and partition the pool for sensitive tenants. Source: llm-d KV-cache-aware routing | consistent hashing | Kubernetes pod IP reuse
3. With no bug at all: the timing side channel
Even a perfectly correct cache leaks, because a cache hit is faster than a miss. In the NDSS 2025 "PROMPTPEEK" attack, an adversary sends crafted probe sequences and times the responses to detect which prefixes are already cached, reconstructing another user's prompt token by token. A black-box study found Claude, DeepSeek, and Azure OpenAI all sharing caches in a way that exposes this, and Anthropic has publicly investigated an unconfirmed report of Claude returning another user's response during an outage. The defenses are to disable cross-tenant prefix sharing on sensitive paths and apply the entropy-based cache obfuscation the researchers propose. Source: PROMPTPEEK (NDSS 2025) | "The Early Bird Catches the Leak"
Underneath all three is the same uncomfortable trade: the optimizations that make inference fast, prefix-cache sharing, continuous batching, cross-node KV pools, are the very things that break isolation. You cannot maximize throughput and isolation at once, so spend the tax where the trust boundary is: share caches and batches freely within a tenant, never across tenants, put the heavy guards on the public front door, and keep a fast path for trusted internal traffic. Then load-test isolation on purpose, driving concurrent traffic from many distinct identities and asserting that no response ever crosses a boundary. Treat any speed optimization that quietly crosses a trust boundary as a security bug, because that is exactly what every leak above is. Source: vLLM production deployment guide
The call is coming from inside the house
You can do all four perfectly and still lose on the first load_model(), because the weights themselves can be the attack. The standard PyTorch checkpoint format is a compressed Python pickle, and unpickling runs arbitrary code by design. In February 2025, ReversingLabs found models on Hugging Face carrying reverse-shell payloads that executed the moment the file was deserialized. The technique, "nullifAI," used malformed and oddly compressed pickle files to slip straight past Picklescan, the platform's own malware scanner, while Python's more permissive loader ran them anyway.
So treat model weights with the same suspicion as any third-party binary you would not run blindly. Prefer the safetensors format, which is pure data and cannot execute code, over pickle-based checkpoints. Pin and verify the exact model revisions you load, scan them, and pull from sources you trust rather than whatever ranks first in a search. A sealed box does you no good if you carry the burglar in with the furniture.
It is not only language models
Everything so far applies just as much to the classical models still doing most of the world's inference: fraud classifiers, recommendation engines, vision and speech models, embeddings. The serving stack is the same shape and fails the same way. TorchServe, PyTorch's own model server, shipped a management API that bound to all interfaces with no authentication. Oligo's "ShellTorch" research chained that exposed console with a server-side request forgery and a YAML deserialization bug (CVE-2023-43654, CVSS 9.9) into full remote code execution, and found thousands of vulnerable instances at major organizations. The lesson is identical to the LLM engines: never expose the management or inference port, and SEAL the box.
The supply-chain warning generalizes too, and gets worse. A classical model is just as likely to be a pickle, and TensorFlow's SavedModel format can embed operations that execute code on load, so a downloaded vision model can own your server before it classifies a single image. Prefer formats that are pure data, ONNX or safetensors, and treat every downloaded model as untrusted code.
What classical ML adds is a whole category of attack that lives entirely inside legitimate-looking queries to your prediction API. Because these models hand back confidence scores, an attacker with nothing but query access can mount model extraction (cloning your proprietary model by querying it enough), model inversion (reconstructing sensitive training data from the scores), or membership inference (proving a specific person's record was in your training set, a compliance problem all by itself). All three need many crafted queries, which is also the defense: rate-limit and monitor for abnormal query patterns, return only top-k labels or coarse-grained scores instead of full-precision confidences, and add noise or differential privacy where the data is sensitive. The same discipline that stops token freeloading on an LLM, watching the volume and shape of requests, stops model theft on a classifier. Source: Oligo (ShellTorch) | Model inversion attacks
The maximalist north star
If you want to see where this logic ends, Vitalik Buterin has sketched it: an LLM setup that runs entirely on local hardware, fully air-gapped, with every dangerous operation sandboxed and the external internet treated as fundamentally hostile.
"Privacy, security and self-sovereignty as non-negotiable."
Most production apps will land somewhere short of full air-gapping, because a model that cannot reach anything is also a model that cannot do much. But the direction is the right one, and it is the inverse of the default you get out of the box. You do not open the box up and then bolt on security; you start from sealed and open the minimum each feature actually requires. Source: Vitalik Buterin
So where does a WAF fit, again?
On the self-hosted path the WAF has a clear, concrete home: it is the lock on the "S" in SEAL, the authenticating, rate-limiting reverse proxy that stands between the public internet and your private inference subnet. That is real and necessary. What it is not, any more than in Part 1, is a defense against the model being talked into something through content it reads. Those are two different jobs at two different layers. Which brings us to the question the whole series has been circling: the vendors now selling "AI firewalls" claim to do both. In Part 3 we stop summarizing their marketing and actually test them, including where their prompt-injection detection can be bypassed.
The takeaway
Self-hosting buys you control and privacy, and charges you the full bill of running a server that happens to contain a GPU and a language model. CLAMP the model; SEAL the box. Shut the door, keep egress on a leash, airgap and patch the runtime, and lock down tenancy, then verify the weights you load before any of it matters. None of it is novel, and that is the point: the 600 FortiGate devices fell to an exposed port and a weak password, not a genius exploit, and your inference server is sitting in exactly the same place on exactly the same internet.
Frequently Asked Questions
Which inference engine should I run, and is any of them safe to expose directly?
For production multi-user serving the real choices are vLLM (the default), SGLang (strong on shared-context workloads like chat, RAG, and agents), or TensorRT-LLM behind NVIDIA Triton for maximum throughput on NVIDIA hardware. Hugging Face's TGI entered maintenance mode in 2026 and now points users elsewhere, and Ollama and llama.cpp are the dev and edge tier rather than production engines. And no, none of them is safe to expose directly: they serve an OpenAI-compatible API whose authentication is optional and off by default. The expected pattern is to run the engine on a private network and front it with an authenticating gateway such as Envoy AI Gateway, KServe, or LiteLLM. Treat the engine as an internal service, never an internet-facing one.
Can other users read my prompts on a shared inference server?
Potentially, yes. To go faster, inference servers share KV-cache and prefix caches across requests, and that shared state creates a timing side channel: an attacker who measures response latency can detect cache hits and reconstruct another user's prompt token by token, with research reporting success rates approaching 90%. If you serve multiple tenants from one model, isolate caches and GPU memory across trust boundaries and enforce per-tenant quotas. This is the "L" (Lock down tenancy) in SEAL.
Can a model file itself contain malware?
Yes. The common PyTorch checkpoint format is a compressed Python pickle, and loading a pickle can execute arbitrary code. In 2025, researchers found Hugging Face models carrying reverse shells that ran the instant the file was loaded, slipping past the platform's own scanner. Prefer the safetensors format, which holds only data and cannot execute code, pin and verify exact model revisions, scan what you download, and pull only from sources you trust.
I followed CLAMP from Part 1. Do I still need all of this?
Yes. CLAMP secures the model's behavior, the prompt-injection and output-handling problems that exist no matter who hosts the model. SEAL secures the infrastructure you take on when you host it yourself: the network, the serving framework, multi-tenant memory, and the supply chain of weights. They are complementary layers. On the API path you mostly need CLAMP; on the self-hosted path you need both, because you now own everything from the HTTP listener down to the GPU.
Under heavy traffic, users report seeing each other's responses. What causes that?
In an inference server it is usually the KV cache, not a breach. To go fast, vLLM and SGLang share KV blocks across requests with a common prefix; under load the cache fills, blocks are evicted and reused, and a mis-keyed or use-after-free block can return one user's cached tokens to another. That same shared cache also leaks through a timing side channel. Application caches fail the same way, as the March 2023 ChatGPT Redis incident showed. The fixes: enable vLLM's per-tenant cache salting (or disable cross-tenant prefix caching), key any application cache to the authenticated tenant, never cache personalized responses at the CDN, and load-test isolation with concurrent traffic from many identities. It is invisible at low traffic and catastrophic at high traffic.
Does any of this apply to non-LLM models?
Yes, and some of it only applies there. The serving stack and supply chain are identical: TorchServe's ShellTorch flaws (CVE-2023-43654) chained an exposed management API into remote code execution on thousands of servers, and TensorFlow SavedModel files can run code on load just like a pickle, so SEAL the box and prefer ONNX or safetensors. Classical models add query-based attacks that LLMs mostly do not face: model extraction (cloning your model), model inversion (reconstructing training data), and membership inference (proving a record was in your training set). Defend them by rate-limiting the prediction API, returning only top-k or coarse confidence scores, and monitoring for abnormal query patterns.
Will these security controls hurt inference performance?
Yes, and you should plan for it rather than be surprised. The optimizations that make inference fast and the controls that make it safe usually pull against each other: prefix-cache and KV-cache sharing can triple throughput but leak across tenants, continuous batching boosts utilization but risks crossing user streams, and an inline prompt-injection classifier adds a model call to every request. The answer is not to skip the controls but to spend the cost where the trust boundary is: share caches and batches within a single tenant, isolate them across tenants, put the heavy guards on the public front door, and keep a fast path for trusted internal traffic. Measure p99 latency, throughput, and cost per request as you add each layer, and treat any speed optimization that quietly crosses a trust boundary as a security bug.
How do you keep the KV cache warm across a GPU cluster without leaking across tenants?
You need KV-cache-aware routing so a follow-up request reaches the replica that holds its cached prefix. vLLM and llm-d do this by having each pod publish per-block KVEvents to a gateway that scores pods by prefix-block affinity plus memory load; SGLang's router uses a radix-trie mirror with consistent hashing; and cache can be pooled across nodes with LMCache or Mooncake. The catch is that all of this works by co-locating and sharing prefixes, which concentrates tenants on the same cache, and the risk peaks during autoscaling, when a stale routing index, a hash-ring remap, or Kubernetes pod-IP reuse can send a request to the wrong backend. Keep it safe by routing and salting on (tenant, prefix) rather than prefix alone, partitioning the pool or dedicating replicas for sensitive tenants, and encrypting KV transfer between nodes. With tenant-keyed salting, a mis-routed request degrades to a cache miss instead of a cross-user leak. The cost is a lower cross-tenant cache hit rate.